

 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen


Datentypen und Variablen
Einführung

Haben Sie bereits in Sprachen wie C und C++ programmiert? Deswegen glauben Sie, dass Sie bereits genug über Datentypen und Variablen wissen? Sie wissen sicherlich viel, das stimmt, aber nicht genug, wenn es um Python geht. Deshalb lohnt es sich auf jeden Fall hier weiterzulesen.
Es gibt gravierende Unterschiede in der Art wie Python und C bzw. C++ Variablen behandeln. Vertraute Datentypen wie Ganzzahlen (Integer), Fließkommazahlen (floating point numbers) und Strings sind zwar in Python vorhanden, aber auch hier gibt es wesentliche Unterschiede zu C und C++. Dieses Kapitel ist also sowohl für Anfänger als auch für fortgeschrittene Programmierer zu empfehlen.
Benutzung von Variablen
Benötigt man in einem Python-Programm beispielsweise den Wert 42, so kann man sich diesen mittels einer Variablen "speichern". Dies geschieht mit einer Zuweisung:
i = 42
Diese Anweisung bezeichnet man als Zuweisung oder auch als Definition einer Variablen. Das Gleichheitszeichen darf man nicht als mathematisches Gleichheitszeichen sehen, sondern als "der Variablen i wird der Wert 42 zugewiesen", d.h. die Variable i zeigt nach der Zuweisung auf den Wert 42.
Wir können nun diese Variable zum Beispiel benutzen, indem wir ihren Wert mit print ausgeben lassen:
i = 42
print("Wert von i: ", i)
Wir können sie aber auch auf der rechten Seite einer Zuweisung in einem Rechenausdruck verwenden, dessen Ergebnis dann einer Variablen zugewiesen wird:
x = i / 3.0 + 5.8
print(x)
Man kann eine Variable auch gleichzeitig auf der rechten und der linken Seite einer Zuweisung benutzen. Im Folgenden erhöhen wir den Wert der Variablen i um 1:
i = 1
i = i + 1
print(i)
Für obige Schreibweise wird üblicherweise die sogenannte erweiterte Zuweisung verwendet:
i = 1
i += 1
print(i)
Vom Ergebnis her gesehen sind die beiden Möglichkeiten identisch. Allerdings gibt es einen Implementierungsunterschied. Bei der erweiterten Zuweisung muss die Referenz der Variablen i nur einmal ausgewertet werden. Bei Datentypen wie Listen, die wir noch nicht behandelt haben, kann es zu extremen Laufzeitproblemen kommen, wenn man keine erweiterte Zuweisung verwendet. Darauf gehen wir jedoch erst später ein. Erweiterte Zuweisungen gibt es auch für die meisten anderen Operatoren, wie ,,-'', ,,*'', ,,/'', ,,**'', ,,//'' (ganzzahlige Division), ,,%'' (Modulo).
In Python kann zur Laufzeit sowohl der Wert einer Variablen geändert werden, als auch der Typ einer Variablen. Präziser: Ein neues Objekt eines beliebigen Typs wird der Variablen zugewiesen. Wir verdeutlichen dies in folgendem Beispiel:
i = 42 # Typ wird implizit auf Integer gesetzt
i = 41 + 0.11 # Typ wird in float geändert
i = "fünfzig" # Jetzt ist es ein string
Regeln zu Benennung von Variablen
In jeder Programmiersprache gibt es Regeln für die Benennung von Variablen, die man manchmal auch Bezeichner nennt.
In Python gelten folgende Regeln:
Ein gültiger Bezeichner ist eine nicht leere Folge von Zeichen beliebiger Länge mit:
- Das Startzeichen kann der Unterstrich "_" oder ein Groß- oder Kleinbuchstabe sein. Dies bezieht sich nicht nur auf das lateinische Alphabet. Es kann sich auch um griechische, kyrillische, Devanagari oder einer anderen auf der Erde vorkommenenden Schrift sein. Naja, klingonisch geht auch.
- Die Buchstaben nach dem Startzeichen können alles sein, was als Startzeichen zulässig ist, plus die Ziffern.
- Nur eine Warnung für Windows-verwöhnte Benutzer: Bei Bezeichnern wird zwischen Groß- und Kleinschreibung unterschieden!
- Python-Schlüsselwörter sind als Bezeichnernamen nicht erlaubt. (z.B.
if,while)
Beispiele mit gültigen Variablennamen:
speed = 123.4
ταχύτητα = 89 # Greek
गति = 10 # Hindi: pronounced gati
hız = 12 # Turkish
speed, ταχύτητα, गति, hız
Namenskonventionen für Variablen
Wir haben bereits festgestellt, dass wir manchmal Namen für Variablen oder Funktionen benötigen, die mehr als ein Wort beinhalten. Wir haben zum Beispiel "maximum_height" verwendet. Der Unterstrich fungiert hier als Wort-Trenner, denn Leerzeichen sind nicht möglich. Einige Entwickler nutzen gerne die s.g. Camel-Case-Schreibweise. Diese würden stattdessen "MaximumHeight" schreiben. Es ist wohl Geschmacksache welche Schreibweise man verwendet. Ich persönlich ziehe "die_natürliche_art" der "DieNatürlicheArt" vor. Der Style Guide für Python Code empfiehlt ebenfalls die Unterstrich-Schreibweise sowohl für Variablen, als auch für Funktionen.
Variablen in anderen Sprachen
Dieses Unterkapitel ist speziell für C, C++ und Java-Programmierer gedacht, weil diese Programmiersprachen Standarddatentypen anders behandeln als Python. Diejenigen, die Python als erste Programmiersprache lernen, können gerne zum nächsten Unterkapitel springen.
In den meisten Programmiersprachen, wie z.B. C, ist es so, dass eine Variable einen festen Speicherplatz bezeichnet, in dem Werte eines bestimmten Datentyps abgelegt werden können. Während des Programmlaufes kann sich der Wert der Variable ändern, aber die Wertänderungen müssen vom gleichen Typ sein. Also kann man nicht in einer Variablen zu einem bestimmten Zeitpunkt eine Integerzahl gespeichert haben und dann diesen Wert durch eine Fließkommazahl überschreiben. Ebenso ist der Speicherort der Variablen während des gesamten Laufes konstant, kann also nicht mehr geändert werden. In Sprachen wie C und C++ wird der Speicherort bereits durch den Compiler fixiert.
Was wir bisher gesagt haben, trifft auf Sprachen wie C, C++ und Java zu. In diesen Sprachen müssen Variablen auch deklariert werden, bevor sie benutzt werden können.
int x; int y;
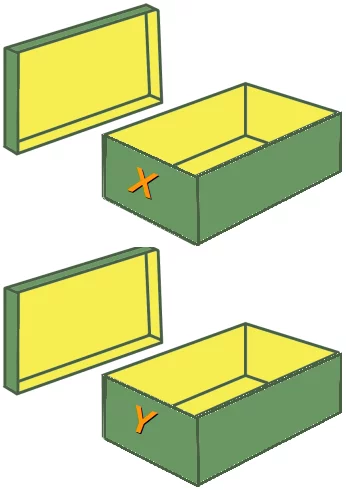
Solche Deklarationen stellen sicher, dass das Programm Speicher für zwei Variablen mit den Namen x und y reserviert. Die Variablen Namen stehen für den Speicherort. Es ist so wie die beiden leeren Schuhkartons im Bild auf der rechten Seite. Diese beiden Schuhkartons sind mit x und y etikettiert. So wie die Schuhkartons ist auch der Speicher für x und y leer.
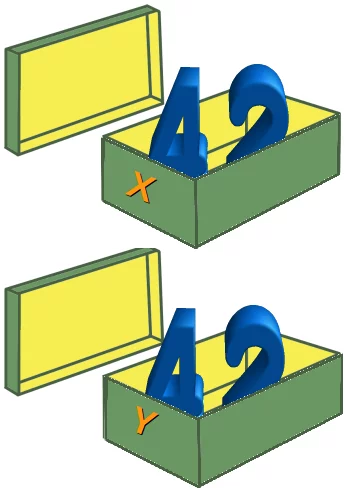
Will man Werte im Speicher ablegen, so kann man dies mit Zuweisungen verwirklichen. Die Art, wie man Werte zuweist, ist in den meisten Programmiersprachen gleich. Meistens wird das Gleichheitszeichen benutzt. Der Wert auf der rechten Seite wird in der Variablen auf der linken Seite gespeichert. Wir werden im folgenden C-Beispiel an beide vorher deklarierte Variablen den Wert 42 zuweisen. Das Ergebnis sehen wir auch im Bild veranschaulicht.
x = 42; y = 42;
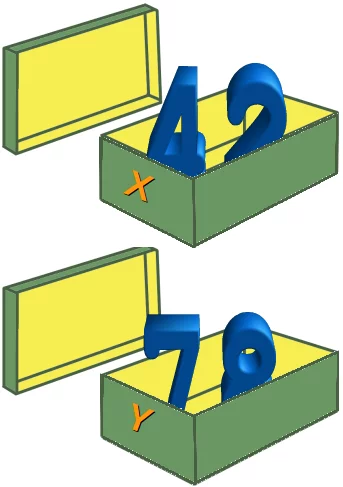
Es ist nicht schwer zu verstehen, was passiert, wenn wir einen neuen Wert einer der beiden Variablen zuweisen, zum Beispiel den Wert 78 der Variablen y.
y = 78;
Der Wert der Speicherstelle von y wurde ausgetauscht.
Wir haben nun gesehen, dass in Programmiersprachen wie C, C++ oder Java jede Variable einen eindeutigen Datentyp hat oder besser haben muss. Das bedeutet, dass falls beispielsweise eine Variable vom Typ Integer ist, sie nur Integer-Werte aufnehmen kann. In diesen Programmiersprachen müssen Variablen auch vor ihrer Benutzung deklariert werden. Deklaration bedeutet Bindung an einen Datentyp, der dann für den gesamten Programmablauf unveränderlich ist.
Variablen in Python
In Python haben wir eine gänzlich andere Situation. Zunächst einmal bezeichnen Variablen in Python keinen bestimmten Typ und deshalb benötigt man auch in Python keine Typdeklaration.
Eingangs haben wir bereits gesehen, dass Variablen durch Zuweisungen entstehen oder verändert werden:
i = 42
Variablen sind Objekt-Referenzen
Wir wollen einen genaueren Blick auf die Implementierung von Variablen in Python werfen. Variablen referenzieren Objekte in Python. Die eigentlichen Daten sind jedoch im Objekt enthalten.
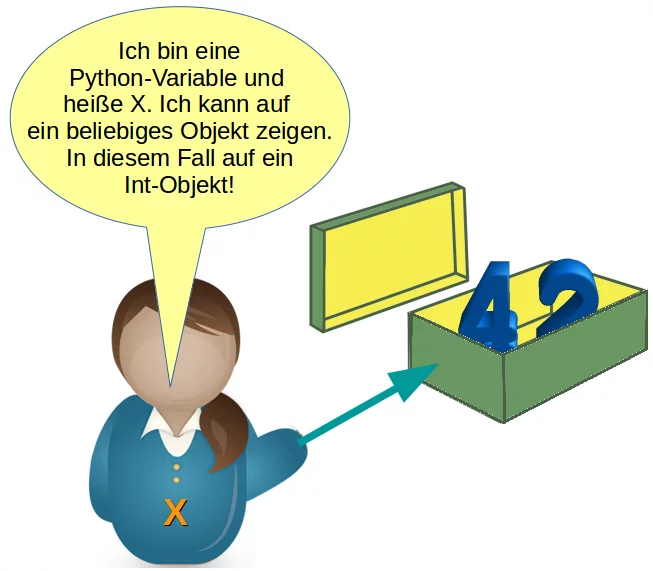
Da Variablen Objekte referenzieren und Objekte einen beliebigen Datentyp haben können, ist es nicht möglich, Variablen mit Datentypen zu verknüpfen. Dies ist ein riesiger Unterschied zu C, C++ oder Java, wo Variablen fest mit einem Datentyp assoziiert sind. Diese Verknüpfung gilt solange das Programm läuft.
Aus diesem Grund ist es möglich in Python Code wie den folgenden zu schreiben:
x = 42
print(x)
x = "Jetzt referenziert x einen String"
print(x)
Nun wollen wir etwas anderes aufzeigen. Betrachten wir den folgenden Code, in dem wir ein Integer-Objekt 42 anlegen und dieses der Variablen x zuweisen. Danach weisen wir x der Variablen y zu. Dies führt dazu, dass nun beide Variablen dasselbe Objekt referenzieren:
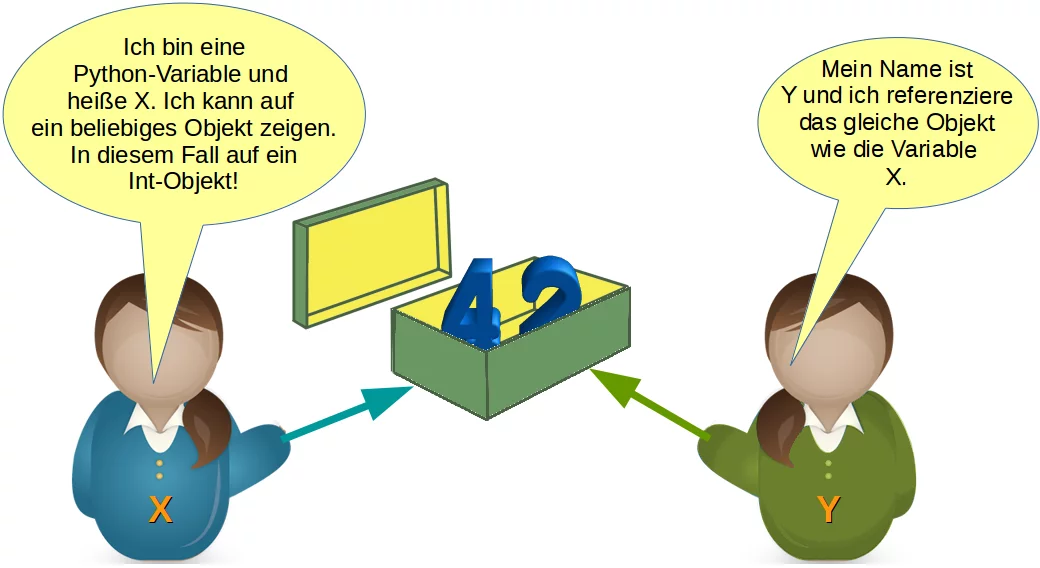
Was wird passieren, wenn wir nun die Zuweisung y = 78 ausführen? Python wird zuerst ein neues Integer-Objekt mit dem Inhalt 78 erzeugen und dann wird die Referenz von y auf dieses Objekt geändert, wie wir im folgenden Bild sehen können:
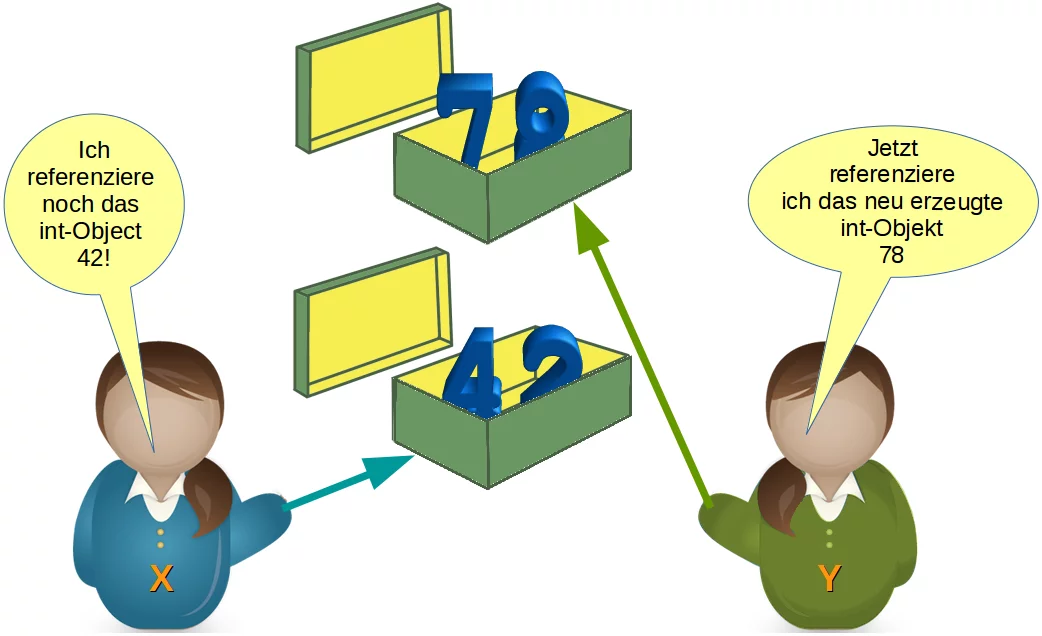
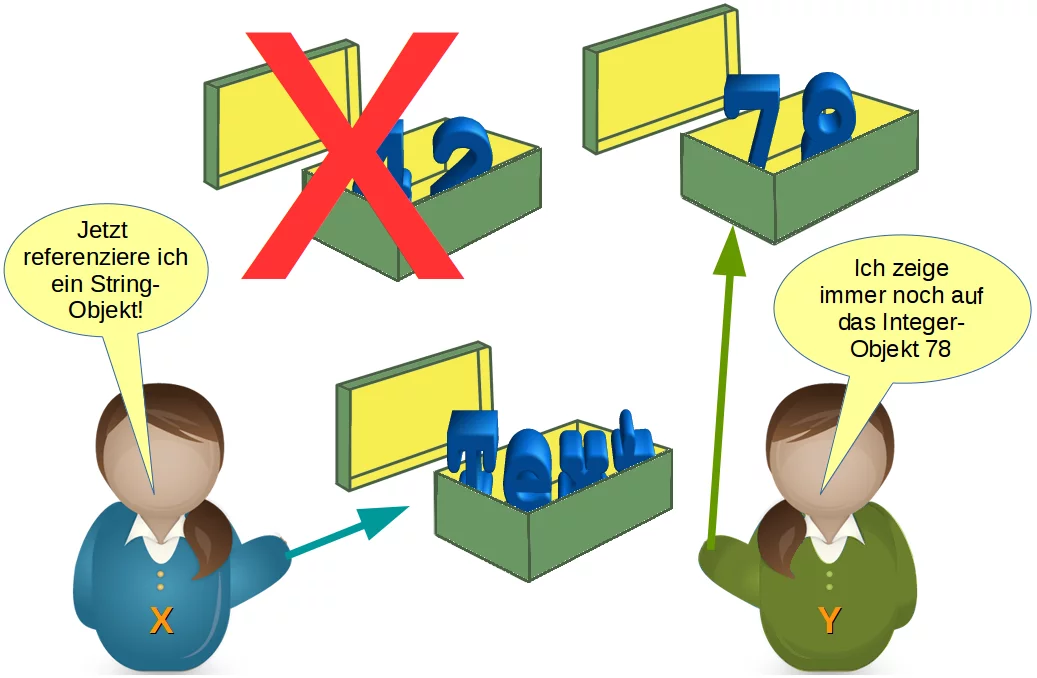
Höchst wahrscheinlich würden wir noch weitere Änderungen an den Variablen im Lauf unseres Programmes erfahren. Zum Beispiel könnte der Variablen x ein String zugewiesen werden. Das Integer-Objekt "42" wird damit verwaist. Es muss von Python entfernt werden, da es von keiner anderen Variablen referenziert wird.
id-Funktion
Es stellt sich die Frage, wie man das oben gesagte überprüfen kann. Dazu bietet sich die Identitätsfunktion id() an. Die Identität einer Instanz dient dazu, sie von allen anderen Instanzen zu unterscheiden. Die Identität ist eine Ganzzahl, und sie ist innerhalb eines Programmes eindeutig. Die Identitätsfunktion id() liefert die Identität. So kann man prüfen, ob es sich um eine bestimmte Instanz handelt und nicht nur um eine mit dem gleichen Wert und Typ. Wir geben nochmals das obige Beispiel ein, lassen uns aber jeweils die Identität ausgeben:
x = 42
id(x)
y = x
id(x), id(y)
y = 78
id(x), id(y)
Wir stellen fest, dass sich die Identität erst ändert, nachdem wir y einen neuen Wert zugewiesen haben. Die Identität von x bleibt gleich, d.h. der Speicherort von x wird nicht geändert.
Python Schlüsselwörter
Abgesehen von den oben genannten Regeln für die Nutzung von Bezeichnern, dürfen diese nicht mit den folgenden Python-Schlüsselwörtern übereinstimmen: and, as, assert, break, class, continue, def, del, elif, else, except, False, finally, for, from, global, if, import, in, is, lambda, None, nonlocal, not, or, pass, raise, return, True, try, while, with, yield
Verändern von Datentypen und Speicherplätzen
Programmieren bedeutet Verarbeitung von Daten. Daten werden in einem Python-Programm durch Objekte repräsentiert. Diese Objekte können in Python
- integriert (built-in) sein, d.h. sie gehören zum Standardsprachumfang, oder
- sie kommen aus Erweiterungsmodulen oder
- sie werden in der Anwendung des Benutzers erzeugt.
Es gibt also verschiedene "Arten" von Objekten für verschiedene Datentypen. Schauen wir uns die verschiedenen Datentypen an, die bereits in Python integriert sind.
x = 4321
~Eine Oktalzahl markiert man, indem man ein "0o", d.h. Ziffer Null gefolgt von einem kleinen "o" (oder einem großen "O"), der Zahl voranstellt:x = 0o11
print(x)
~Eine Hexadezimalzahl (Hexzahl) markiert man mit einem vorangestellten "0x" oder "0X":x = 0x1A
print(x)
~Literale als Binärzahl lassen sich ähnlich leicht darstellen. Die führende Null wird nun von einem kleinen "b" oder großen "B" gefolgt:x = 0b101010
x
Mit den Funktionen hex, bin, oct kann man eine Integer-Zahl in einen String wandeln, der der Stringdarstellung der Zahl in der entsprechenden Basis entspricht:
x = hex(19)
x
type(x)
x = bin(65)
x
x = oct(65)
x
oct(0b101101)
In Python2 wurde noch zwischen "int" und "long int" unterschieden. In Python3 gibt es nur noch "Integer", die beliebig lang sein können:
x = 787366098712738903245678234782358292837498729182728
print(x)
x * x * x
10 / 3
Auch wenn das Ergebnis den meisten Mathematikern und Informatikern logisch erscheinen wird, ist es nicht das, was die meisten Leute an dieser Stelle erwarten würden. Die zugrundeliegende Idee bei dem obigen Ergebnis ist nämlich, dass bei der Division eines Integers durch einen weiteren Integer, ein Integer-Wert als Ergebnis heraus kommt, d.h. dass eine Operation innerhalb ihrer Datentypen abgeschlossen ist. Dies wird mit einer zusätzlichen Rundung (floor division) erreicht. Im obigen Beispiel kann man es gut erkennen.
Um dies zu vermeiden nutzt Python 3 keine Rundung bei der Division (true division). Wenn Integer durch Integer dividiert werden, entstehen Float-Werte.
x = 11
y = 3
z = x / y
type(z)
print(z)
Die Division mit Abschneiden ("floor division") kann aber in Python 3 mit "//" erzwungen werden.
z = 10 // 3
type(z)
print(z)
String-Interna

Die Aufgabe der Computer der ersten Generation in den Vierziger- und Fünfzigerjahren des vorigen Jahrhunderts bestand - wegen technischer Restriktionen - im Wesentlichen in der Lösung numerischer Probleme. Textverarbeitung war zu dieser Zeit im Wesentlichen nur ein Traum. Heutzutage beschäftigen sich Computer in einem großen Umfang mit Textverarbeitung; die bedeutendsten Anwendungen stellen wohl die Suchmaschinen, allen voran Google, dar. Um mit Texten umzugehen, benötigen Programmiersprachen geeignete Datentypen. So werden Strings in nahezu allen modernen Programmiersprachen genutzt, um textuelle Informationen zu verarbeiten. Logisch gesehen ist ein String - wie Text - eine Folge von Zeichen. Die Frage bleibt, was ein Zeichen (englisch character) darstellt. In einem Buch oder auch einem Text, wie beispielsweise dem, den Sie gerade lesen, werden die Zeichen grafisch dargestellt, sogenannte Grapheme, die aus Linien und Kurven bestehen, die in bestimmten Verhältnissen angeordnet sind, sich überschneiden und so weiter.

In der Computertechnik stellt ein Character eine Informationseinheit dar. Die Zeichen (englisch characters) entsprechen Graphemen, den zugrundeliegenden Einheiten der geschriebenen und gedruckten Sprache. Vor Unicode gab es nur eine Eins-zu-eins-Beziehung zwischen Zeichen und Bytes, d.h., jedes einzelne Zeichen wurde durch ein Byte im Computer repräsentiert. Ein solches Byte repräsentiert dann das logische Konzept des Zeichens und steht für die gesamte Klasse der Grapheme dieses Zeichens. In dem Bild auf der rechten Seite zeigen wir verschiedene grafische Repräsentationen des Buchstabens "A", also "A" in verschiedenen Fonts. Wir sehen, dass es im Druck verschiedene grafische Darstellungen des abstrakten Konzeptes "A" gibt. (Übrigens geht unser heutiges A auf eine ägyptische Hieroglyphe zurück, die einen Ochsenkopf symbolisiert) Alle grafischen Darstellungen haben bestimmte Eigenschaften gemeinsam. Ein großes "A" wird in ASCII mit dem Byte-Wert 65 kodiert. Die meisten auf ASCII beruhenden Zeichenkodierungen, wie beispielsweise ISO-8859, sind allerdings auf 256 Bytes oder Zeichen beschränkt. ASCII selbst ist sogar auf 128 Zeichen beschränkt. Das ist natürlich genug für Sprachen wie Englisch, Deutsch oder Französisch, aber bei weitem nicht genug für Schriftsysteme, wie sie das Chinesische oder das Japanische erfordern. Wegen dieser Probleme wurde Unicode ins Leben gerufen. Unicode ist ein Standard, der entworfen worden ist, um jedes beliebige Zeichen von jeder Schrift darstellen zu können. Verschiedene Schriftsysteme können damit auch gleichzeitig verwendet werden, so kann ein Text in lateinischer Schrift beispielsweise mit kyrillischem, arabischen oder sogar chinesischem Text gemischt werden.
Jeder Buchstabe bzw. Zeichen wird in Unicode als eine 4-Byte große Zahl dargestellt, so entspricht beispielsweise das große "A" dem Wert U+0041. Während der erweiterte ASCII-Code auf 256 Zeichen pro Zeichensatz beschränkt ist, gibt es bei Unicode praktisch gesehen keinerlei Einschränkungen, denn mit 4 Bytes kann man 2564 Zeichen (also mehr als 4,29 Milliarden) abbilden. (Wegen der gewählten Zuordnung gibt es allerdings "nur" 1.112.064 mögliche Zeichen) Nur wenig mehr als 100.000 Zeichen also weniger als 1% des theoretisch möglichen Zeichenraumes sind in Unicode belegt. Aber die Frage bleibt, wie man Unicode implementiert. Wir könnten natürlich 4 Bytes pro Zeichen verwenden und damit den Standard Eins-zu-eins umsetzen. Aber das wäre eine Speichervergeudung. Ein Textdokument würde dann viermal so viel Speicherplatz benötigen wie bisher unter ASCII.
Es gibt verschiedene Zeichencodierungen für Unicode:
| Name | Beschreibung |
| UTF-32 | Hierbei handelt es sich um eine Eins-zu-eins Abbildung, d.h. jedes Unicode-Zeichen, was ja einer 4-Byte großen Zahl entspricht, wird auch in 4 Bytes abgespeichert. Ein Vorteil dieser Kodierung besteht darin, dass das n-te Zeichen in einem String in linearer Zeit berechnet (gefunden) werden kann, weil das n-te Zeichen immer an der Position 4×N vom Stringanfang aus gesehen beginnt. Der hohe Speicherverbrauch dieser Kodierung ist allerdings ein Problem. |
| UTF-16 | Kaum jemand benötigt mehr als 65535, daher ist UTF-16, welches nur 2 Bytes benötigt, eine effizientere Alternative zu UTF-32. Ein Problem, dass sowohl UTF-32 und UTF-16 betrifft besteht darin, dass die Byte-Reihenfolge eines Zeichens vom Betriebssystem abhängt. |
| UTF-8 | UTF8 ist eine Kodierung für Unicode mit variabler Länge, d.h. verschiedene Zeichen können verschiedene Kodierungslängen haben. So benötigen ASCII-Zeichen nur ein Byte pro Zeichen, die sogar dem original ASCII-Zeichensatz für die ersten 128 Zeichen entsprechen. Das bedeutet, dass diese Zeichen zwischen UTF-8 und ASCII ununterscheidbar sind. Aber die sogenannten "Erweiterten Lateinischen" Zeichen, denen beispielsweise die Umlaute wie ä, ö, ü angehören, benötigen zwei Bytes. Chinesische Zeichen benötigen drei und nur ganz spezielle extrem selten benutzte Spezialzeichen benötigen 4 Bytes in UTF-8. Ein Nachteil dieser Methode besteht darin, das n-te Zeichen eines Strings zu bestimmen. Die Berechnungszeit ist dann nicht mehr linear. |
Benutzung von Strings
Ein String, oder Zeichenkette, kann man als eine Sequenz von einzelnen Zeichen sehen.
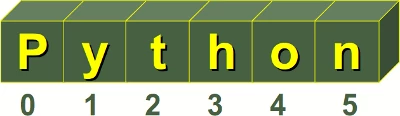
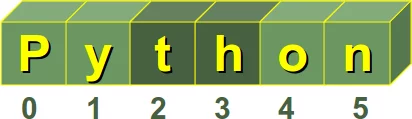
Jedes einzelne Zeichen eines Strings, kann über einen Index angesprochen werden. Im folgenden Beispiel sehen wir, wie der im Bild dargestellte String in Python definiert wird und wie wir auf ihn zugreifen können:
s = "Python"
print(s[0])
print(s[3])
Die Länge eines Strings kann man mit der Funktion len() bestimmen und damit kann man auch einfach beispielsweise auf das letzte oder vorletzte Zeichen eines Strings zugreifen:
s = "Python"
index_last_char = len(s) - 1
print(s[index_last_char])
print(s[index_last_char - 1])
Da es bei der praktischen Arbeit sehr häufig vorkommt, dass man auf einzelne Zeichen eines Strings von hinten zugreifen muss, wäre es sehr lästig, wenn man dies immer über den Umweg durch den Aufruf der Funktion len() machen müsste. Python bietet deshalb eine elegantere Möglichkeit. Die Indices werden auch von rechts durch negative Indices nummeriert, d.h. das letzte Zeichen wird mittels des Index -1, das vorletzte mittels -2 usw. angesprochen. Wir sehen dies in der folgenden Abbildung veranschaulicht:
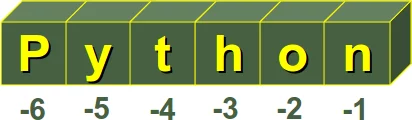
Im Code sieht das wie folgt aus:
s = "Python"
last_character = s[-1]
print(last_character)
Strings können unter Benutzung von
- einzelnen Anführungszeichen (') 'Dies ist ein String mit einfachen Quotes'
- doppelten Anführungszeichen (") "Mayers' Dackel heißt Waldi"
- dreifachen Anführungszeichen (''') oder (""") '''String in dreifachen Anführungszeichen können auch über mehrere Zeilen gehen und 'einfache' und "doppelte" Anf.zeichen enthalten.'''
angegeben werden.
Wichtige Stringfunktionen
Ein paar String-Funktionen:
- Konkatenation (englisch: Concatenation)
Diese Funktion dient dazu mittels des "+"-Operators zwei Strings zu einem neuen String zusammenzuhängen:
"Hello" + "World" -> "HelloWorld" - Wiederholung (englisch: Repetition)
Ein String kann wiederholt konkateniert werden. Dazu benutzt man den "*"-Operator.
Beispiel:
"abc" ∗ 3 wird zu "abcabcabc"
oder
"." ∗ 5 wird zu "....." - Indexing
"Python"[0] -> "P" - Slicing
Das englische Verb "to slice" bedeutet in Deutsch "schneiden" oder auch "in Scheiben schneiden". Letztere Bedeutung entspricht auch der Funktion von Slicing in Python. Man schneidet sich gewissermaßen eine "Scheibe" aus einem String heraus. [2:4] bedeutet im folgenden Ausdruck, dass wir aus dem String "Python" einen Teilstring herausschneiden, der mit dem Zeichen des Index 2 (inklusive) beginnt und bis zum Index 4 (exklusive) geht:
"Python"[2:4] -> "th"
- Länge eines Strings
len("Python") -> 6
s = "Some things are immutable!"
s[-1] = "."
Besonderheiten bei Strings
Einen besonderen Effekt können wir bei Strings feststellen. Im folgenden Beispiel wollen wir dies veranschaulichen. Dazu benötigen wir noch den "is"-Operator. Sind a und b zwei Strings, dann prüft "a is b", ob a und b die gleiche Identität (Speicherort) haben. Wenn "a is b" gilt, dann gilt auch "a == b". Aber wenn "a == b" gilt, dann gilt natürlich nicht notwendigerweise auch "a is b"! Nun wollen wir untersuchen, wie Strings in Python abgespeichert werden. Im folgenden Beispiel, erkennen wir, dass a und b sich den gleichen Speicherort teilen, obwohl wir diesmal keine Zuweisung der Art "b = a" verwendet haben:
a = "Linux"
b = "Linux"
a is b
Wie sieht es jedoch aus, wenn der verwendete String länger ist? Im folgenden verwenden wir als String den längsten Ortsnamen der Welt. Eine Gemeinde mit etwas mehr als 3000 Einwohnern im Süden der Insel Anglesey in der gleichnamigen Grafschaft im Nordwesten von Wales:
a = "Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch"
b = "Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch"
a is b
Aber Vorsicht ist geboten, denn was für eine Gemeinde in Wales funktioniert, schlägt beispielsweise für Baden-Württemberg fehl:
a = "Baden-Württemberg"
b = "Baden-Württemberg"
a is b
a == b
Also an der geographischen Lage kann es nicht liegen, wie man im folgenden Beispiel sieht. Es sieht vielmehr so aus, als dürften keine Sonderzeichen oder Blanks im String vorkommen.
a = "Baden!"
b = "Baden!"
a is b
a = "Baden1"
b = "Baden1"
a is b
Escape- oder Fluchtzeichen
Es gibt Zeichenfolgen, die den Textfluss steuern, wie zum Beispiel ein Newline (Zeilenvorschub) oder Tabulator. Sie lassen sich nicht auf dem Bildschirm als einzelne Zeichen darstellen. Die Darstellung solcher Zeichen innerhalb von String-Literalen erfolgt mittels spezieller Zeichenfolgen, sogenannter Escape-Sequenzen. Eine Escape-Sequenz wird von einem Backslash \ eingeleitet, gefolgt von der Kennung des gewünschten Sonderzeichens. Übersicht der Escape-Zeichen:
- \ Zeilenfortsetzung
- \ Rückwärtsschrägstrich
- \' Einzelnes Anführungszeichen
- \" Doppeltes Anführungszeichen
- \a Glocke
- \b Rückschritt
- \e Ausmaskieren
- \0 Null
- \n Zeilenvorschub (linefeed, LF)
- \v Vertikaler Tabulator
- \t Horizontaler Tabulator
- \r Wagenrücklauf (carriage return, CR)
- \f Seitenvorschub
- \0XX Oktaler Wert
- \xXX Hexadezimaler Wert
Die Auswertung von Escape-Zeichen kann man verhindern, indem man einem String ein r oder R unmittelbar voranstellt.
Beispiel: r"\n bewirkt einen Zeilenvorschub"
Byte-Strings
Python 3 benutzt die Konzepte Text und (binäre) Daten, statt Strings und 8-bit Strings wie in Python 2.x. Jeder String oder Text in Python 3 ist Unicode, aber kodiertes Unicode wird als Datenstrings in Bytes dargestellt. Der Datentyp für Text ist str; der Datentyp für Daten ist bytes. Es ist nicht möglich Text und Daten (bytes) zu mischen. Versucht man zu mischen, erhält man den Ausnahmefehler TypeError. Während ein String-Objekt eine Folge von Zeichen in Unicode enthält, enthält ein Byte-Objekt eine Folge von Bytes mit den Werten 0 .. 255, die den ASCII-Werten entsprechen. Zur Verdeutlichung ein Beispiel:
x = "Hallo"
t = str(x)
u = t.encode("UTF-8")
print(u)