

 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen

Sequentielle Datentypen
Einführung
 Ein sequentieller Datentyp ist ein Datentyp, der eine Folge von gleichartigen oder verschiedenen Elementen beinhaltet. Die Elemente eines sequentiellen Datentyps haben eine definierte Reihenfolge und dadurch kann man per Indices auf sie zugreifen.
Ein sequentieller Datentyp ist ein Datentyp, der eine Folge von gleichartigen oder verschiedenen Elementen beinhaltet. Die Elemente eines sequentiellen Datentyps haben eine definierte Reihenfolge und dadurch kann man per Indices auf sie zugreifen.
Python stellt die folgenden Datentypen zur Verfügung:
- Zeichenketten (Strings)
- str
Dieser Typ speichert Bytefolgen, also auch reine ASCII-Zeichenketten - unicode
Dieser Datentyp speichert Zeichenfolgen in Unicode ab.
- str
- Listen
In einer Liste kann eine Folge belieber Instanzen gespeichert werden. Eine Liste kann jederzeit während des Programmablaufs wieder geändert werden. - Tupel
In einem Tupel wird wie in einer Liste eine Folge belieber Instanzen gespeichert, aber diese kann dann während des weiteren Programmverlaufs nicht mehr verändert werden.
Indizierung
Betrachten wir den String "Hello World":

Man sieht, dass die Zeichen eines Strings von links nach rechts mit 0
beginnend nummeriert sind. Von hinten (rechts) beginnt man mit -1 zu zählen.
Jedes Zeichen eines Strings kann so eindeutig angesprochen werden, sie können
mit eckigen Klammern indizieren, wie man im folgenden Beispiel sehen kann:
>>> txt = "Hello World" >>> txt[0] 'H' >>> txt[4] 'o'Statt von vorne kann man die Indizes auch von hinten bestimmen:
>>> txt[-1] 'd' >>> txt[-5] 'W'Dies funktioniert genauso für Listen und Tupel, aber zunächst müssen wir uns noch anschauen, wie Listen und Tupel in Python überhaupt aussehen:
Listen können beliebige Python-Objekte enthalten. Im folgenden Beispiel enthält "colours" 3 Strings und die Liste a enthält 4 Objekte, und zwar die Strings "Swen" und "Basel", die Ganzzahl 45 und die Fließkommazahl 3.54. Greift man nun analog zu dem Vorgehen bei Strings auf ein Listenelement mit einem Index zu, erhält man das jeweilige Element. So liefert colours[0] im folgenden Beispiel den String 'red' als Ergebnis.
>>> colours = ['red', 'green', 'blue'] >>> colours[0] 'red' >>> colours ['red', 'green', 'blue'] >>> >>> >>> a = ["Swen", 45, 3.54, "Basel"] >>> a[3] 'Basel' >>>
Ausschneiden (Slicing)
Man kann auch Teile eines sequentiellen Datentyps ausschneiden. Im Falle eines
Strings erhält man dann einen Teilstring oder bei Listen wieder eine Liste. Im
Englischen wird dieses Ausschneiden als "slicing" bezeichnet. Wie bei der
Indizierung benutzt der Slicing-Operator eckige Klammer, aber nun werden statt
einem Wert mindestens zwei Werte erwartet: Anfangswert und Endwert
Man versteht dies am besten an einem Beispiel:
>>> txt = "Hello World" >>> txt[1:5] 'ello' >>> txt[0:5] 'Hello' >>> txt = "Hello World" >>> txt[0:5] 'Hello'Lässt man den Anfangswert weg (z.B. [:5] ), beginnt das ausschneiden am Anfang des Strings (oder der Liste). Analog kann man auch den Endwert weglassen, um alles bis zum Ende zu übernehmen ( z.B. [6:] )
Lässt man Anfangs- und Endwert weg, erhält man den ganzen String (oder entsprechend die ganze Liste oder Tupel) zurück:
'Hello' >>> txt[0:-6] 'Hello' >>> txt[:5] 'Hello' >>> txt[6:] 'World' >>> txt[:] 'Hello World'Das folgende Beispiel zeigt, wie sich dies bei Listen auswirkt:
>>> colours = ['red', 'green', 'blue'] >>> colours[1:3] ['green', 'blue'] >>> colours[2:] ['blue'] >>> colours[:2] ['red', 'green'] >>> >>> colours[-1] 'blue'
Der obige Slicing-Operator funktioniert auch mit drei Argumenten. Das dritte Argument gibt dann an, das wievielte Argument jedesmal genommen werden soll, d.h. s[begin, end, step].
Ausgegeben werden dann die folgenden Elemente von s: s[begin], s[begin + 1 * step], ... s[begin + i * step] solange (begin + i * step) < end ist.
txt[::3] gibt jeden dritten Buchstaben eines Strings aus.
Beispiel:
>>> txt = "Python ist ganz toll" >>> txt[2:15:3] 'tnsgz' >>> txt[::3] 'Ph ta l'
Unterlisten
Listen können auch andere Listen als Elemente enthalten:>>> pers = [["Marc","Mayer"],["Hauptstr. 17", "12345","Musterstadt"],"07876/7876"] >>> name = pers[0] >>> name[1] 'Mayer' >>> adresse = pers[1] >>> adresse[1] '12345' >>> pers[2] '07876/7876' >>> strasse = pers[1][0] >>> strasse 'Hauptstr. 17' >>>
Länge
 Die Länge eines sequentiellen Datentyps entspricht der Anzahl seiner Elemente
und wird mit der Funktion len() bestimmt.
Die Länge eines sequentiellen Datentyps entspricht der Anzahl seiner Elemente
und wird mit der Funktion len() bestimmt.
>>> txt = "Hello World" >>> len(txt) 11 >>>Funktioniert auch genau gleich bei Listen:
>>> a = ["Swen", 45, 3.54, "Basel"] >>> len(a) 4
Verkettung von Sequenzen
Eine sinnvolle und häufig benötigte Operation auf Sequenzen ist die Verkettung (engl. concatenation). Als Operatorzeichen für die Verkettung dient das +-Zeichen. Im folgenden Beispiel werden zwei Strings zu einem verkettet:>>> firstname = "Homer" >>> surname = "Simpson" >>> name = firstname + " " + surname >>> print name Homer Simpson >>>Für Listen geht dies genauso einfach, wie das folgende selbsterklärende Beispiel zeigt:
>>> colours1 = ["red", "green","blue"] >>> colours2 = ["black", "white"] >>> colours = colours1 + colours2 >>> print colours ['red', 'green', 'blue', 'black', 'white']Eine sehr gebräuchliche Methode zur Verkettung bietet der "+=", der in vielen anderen Programmiersprachen vor allem bei numerischen Zuweisungen verwendet wird. Der +=-Operator wird als eine abgekürzte Schreibweise benutzt, so steht
s += tfür die Anweisung:
s = s + t
Prüfung, ob Element in Sequenz enthalten
Bei Sequenzen kann man auch prüfen, ob (oder ob nicht) ein Element in einer
Sequenz vorhanden ist. Dafür gibt es die Operatoren "in" und "not in".
Die Arbeitsweise erkennt man im folgenden Protokoll einer interaktiven Sitzung:
>>> abc = ["a","b","c","d","e"] >>> "a" in abc True >>> "a" not in abc False >>> "e" not in abc False >>> "f" not in abc True >>> str = "Python ist toll!" >>> "y" in str True >>> "x" in str False >>>
Wiederholungen
Für Sequenzen ist in Python auch ein Produkt definiert. Das Produkt einer Sequenz s mit einem Integer-Wert n (s * n bzw. n * s) ist als n-malige Konkatenation von s mit sich selbst definiert.
>>> 3 * "xyz-" 'xyz-xyz-xyz-' >>> "xyz-" * 3 'xyz-xyz-xyz-' >>> 3 * ["a","b","c"] ['a', 'b', 'c', 'a', 'b', 'c', 'a', 'b', 'c']s *= n ist (wie üblich) die Kurzform für s = s * n.
Die Tücken der Wiederholungen
In den vorigen Beispielen haben wir den Wiederholungsoperator nur auf Strings und flache Listen angewendet. Wir können ihn aber auch auf verschachtelte Listen anwenden:>>> x = ["a","b","c"] >>> y = [x] * 4 >>> y [['a', 'b', 'c'], ['a', 'b', 'c'], ['a', 'b', 'c'], ['a', 'b', 'c']] >>> y[0][0] = "p" >>> y [['p', 'b', 'c'], ['p', 'b', 'c'], ['p', 'b', 'c'], ['p', 'b', 'c']] >>>
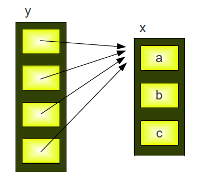 Das Ergebnis ist für Anfänger der Python-Programmierung sehr erstaunlich. Wir haben dem ersten Element
der ersten Unterliste (also y[0][0]) einen neuen Wert zugewiesen und gleichzeitig haben wir automatisch das jeweilige erste Element
aller anderen Unterlisten auch verändert, also y[1][0], y[2][0], y[3][0]
Das Ergebnis ist für Anfänger der Python-Programmierung sehr erstaunlich. Wir haben dem ersten Element
der ersten Unterliste (also y[0][0]) einen neuen Wert zugewiesen und gleichzeitig haben wir automatisch das jeweilige erste Element
aller anderen Unterlisten auch verändert, also y[1][0], y[2][0], y[3][0]
Der Grund für dieses scheinbar merkwürdige Verhalten liegt darin, dass der Wiederholungsoperator "* 4" vier Referenzen auf die Liste x anlegt.