
 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen

# invisible
from IPython.display import HTML, display
import numpy as np
np.core.arrayprint._line_width = 65
Datentyp-Objekt: dtype
dtype
 Das Datentypobjekt 'dtype' ist eine Instanz der numpy.dtype-Klasse. Es kann mit numpy.dtype konstruiert werden.
Das Datentypobjekt 'dtype' ist eine Instanz der numpy.dtype-Klasse. Es kann mit numpy.dtype konstruiert werden.
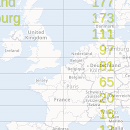
Bis jetzt haben wir in unseren Beispielen von NumPy-Arrays nur grundlegende numerische Typen wie 'int' und 'float' benutzt. Diese NumPy-Arrays enthielten nur homogene Datentypen. dtype-Objekte werden aus einer Kombination von grundlegenden Datentypen erzeugt. Mit Hilfe von dtype sind wir in der Lage "Strukturierte Arrays" zu erzeugen, auch bekannt als "record arrays". Strukturierte Arrays statten uns mit der Möglichkeit aus verschiedene Datentypen in verschiedenen Spalten zu haben. Es gibt somit Ähnlichkeit zu Excel- oder CSV-Dokumenten. Dies ermöglicht es uns somit Daten wie in der folgenden Tabelle mit dtype zu erzeugen:
| Land | Bevölkerungsdichte | Fläche | Einwohner |
|---|---|---|---|
| Niederlande | 393 | 41526 | 16,928,800 |
| Belgien | 337 | 30510 | 11,007,020 |
| Vereinigtes Königreich | 256 | 243610 | 62,262,000 |
| Deutschland | 233 | 357021 | 81,799,600 |
| Liechtenstein | 205 | 160 | 32,842 |
| Italien | 192 | 301230 | 59,715,625 |
| Schweiz | 177 | 41290 | 7,301,994 |
| Luxemburg | 173 | 2586 | 512,000 |
| Frankreich | 111 | 547030 | 63,601,002 |
| Österreich | 97 | 83858 | 8,169,929 |
| Griechenland | 81 | 131940 | 11,606,813 |
| Irland | 65 | 70280 | 4,581,269 |
| Schweden | 20 | 449964 | 9,515,744 |
| Finnland | 16 | 338424 | 5,410,233 |
| Norwegen | 13 | 385252 | 5,033,675 |
Bevor wir jedoch mit komplexen Daten wie den obigen starten, wollen wir dtype an einem sehr einfachen Beispiel einführen. Wir definieren einen Pixel-Datentyp, der einem numpy.uint8-Datentyp entspricht.
Die Elemente der Liste lst werden in Pixel-Typen gewandelt, um das zweidimensionale Array A zu erzeugen. Wir können sehen, dass dabei auch Float-Werte automatisch in Pixel-Datentypen, also numpy.uint8, gewandelt werden.
import numpy as np
Pixel = np.dtype(np.uint8)
print(Pixel)
lst = [ [115, 230.9, 229.2, 234],
[117, 229, 232.1, 235],
[116, 140, 141, 142] ]
A = np.array(lst, dtype=Pixel)
print(A)
Im vorigen Beispiel haben wir lediglich einen neuen Namen für einen Basisdatentyp eingeführt. Damit kann man beispielsweise die Lesbarkeit und Verständlichkeit eines Programmes erhöhen. Dies hat noch nichts mit "Strukturierten Arrays" zu tun, die wir am Anfang dieses Kapitels
unseres Tutorials
erwähnt hatten.
Strukturierte Arrays
ndarrays sind homogene Datenobjekte, d.h. alle Elemente eines Arrays haben den gleichen Datentyp. Der Datentyp dtype hingegen erlaubt es uns, spaltenweise Typen zu deklarieren.
Nun gehen wir den ersten Schritt in Richtung Implementierung der Tabelle europäischer Länder mit den Informationen über Fläche, Bevölkerung und Bevölkerungsdichte.
Wir erzeugen ein strukturiertes Array mit einer Spalte density. Den Datentyp definieren wir als np.dtype([('density', np.int)]). Diesen Datentyp weisen wir der Variablen Density zu. Wir haben die Variable groß geschrieben, damit man sieht, dass es einen Unterschied gibt zu dem density in der Typdefinition selbst. Den Datentyp Density benutzen wir dann in der Definition des NumPy-Arrays, in dem wir die ersten drei Werte benutzen:
import numpy as np
Density = np.dtype([('density', np.int32)])
x = np.array([(393,), (337,), (256,)],
dtype=Density)
print(x)
print("\nDie interne Darstellung:")
print(repr(x))
Wir können auf die density-Spalte zugreifen, indem wir als Schlüssel density eingeben. Es ähnelt einem
Dictionary-Zugriff
in Python:
print(x['density'])
Man wird sich vielleicht wundern, dass wir np.int32 in unserer Definition benutzt haben, aber dass die interne Repräsentierung <i4 zeigt.
In einer dtype-Definition können wir den Typ direkt verwenden, also beispielsweise np.int32, oder wir können einen String benutzen, z.B. i4.
In unserem Beispiel hätten wir unseren dtype auch wie folgt definieren können:
Density = np.dtype([('density', 'i4')])
x = np.array([(393,), (337,), (256,)],
dtype=Density)
print(x)
Das i steht für Integer, und die 4 bedeutet "4 Bytes". Was bedeutet aber das Kleiner-als-Zeichen vor der 4? Wir hätten ebensogut '<i4' schreiben können.
Wir können einem Typ ein '<'- oder ein '>'-Zeichen voranstellen. '<' bedeutet, dass bei der Speicherorganisation Little-Endian verwendet wird, und '>' bedeutet entsprechend, dass Big-Endian verwendet wird. Ohne Präfix wird die natürliche Byte-Reihenfolge des Systems verwendet. Wir demonstrieren dies im folgenden Beispiel, indem wir eine Gleitkommazahl mit doppelter Genauigkeit (double precision floating-point) in verschiedenen Byte-Reihenfolgen definieren:
# little-endian ordering
dt = np.dtype('<d')
print(dt.name, dt.byteorder, dt.itemsize)
# big-endian ordering
dt = np.dtype('>d')
print(dt.name, dt.byteorder, dt.itemsize)
# native byte ordering
dt = np.dtype('d')
print(dt.name, dt.byteorder, dt.itemsize)
Das Gleichheitszeichen '=' steht für die natürliche Byte-Reihenfolge ('native byte ordering'), definiert durch das Betriebssystem. In unserem Fall bedeutet dies Little-Endian, weil wir uns auf einem Linux-Rechner befinden.
Eine andere Sache in unserem Density-Array könnte verwirrend sein. Wir definierten das Array mit einer Liste, die 1-Tupels enthält. Vielleicht fragen Sie sich nun, ob es möglich ist Tupels und Listen austauschbar zu verwenden? Dies ist nicht möglich. Die Tupels werden verwendet um die Records zu definieren - in unserm Fall bestehen diese nur aus der Bevölkerungsdichte ('density') -, und die Liste ist der 'Container' für die Records. Die Tupel definieren die atomaren Elemente der Struktur und die Listen die Dimensionen.
Nun werden wir die Ländernamen, die Flächen und die Populationen zu unserem Typ hinzufügen:
dt = np.dtype([('country', 'S20'),
('density', 'i4'),
('area', 'i4'),
('population', 'i4')])
population_table = np.array([('Netherlands', 393, 41526, 16928800),
('Belgium', 337, 30510, 11007020),
('United Kingdom', 256, 243610, 62262000),
('Germany', 233, 357021, 81799600),
('Liechtenstein', 205, 160, 32842),
('Italy', 192, 301230, 59715625),
('Switzerland', 177, 41290, 7301994),
('Luxembourg', 173, 2586, 512000),
('France', 111, 547030, 63601002),
('Austria', 97, 83858, 8169929),
('Greece', 81, 131940, 11606813),
('Ireland', 65, 70280, 4581269),
('Sweden', 20, 449964, 9515744),
('Finland', 16, 338424, 5410233),
('Norway', 13, 385252, 5033675)],
dtype=dt)
print(x[:4])
Wir können auf jedes Element individuell zugreifen:
print(population_table['density'])
print(population_table['country'])
print(population_table['area'][2:5])
Die Städtenamen sind Instanzen der NumPy-Klasse numpy.bytes_. Man kann sie mit der Funktion str wieder in Unicode-Strings wandeln. Weiter unten werden wir auch sehen, wie man direkt mit Unicode-Strings in dtype-Arrays arbeitet.
s = population_table['country'][0]
print(s, type(s))
s = str(s)
print(s, type(s))
Ein- und Ausgabe von strukturierten Arrays
In den meisten Applikationen ist es notwendig, die Daten aus einem Programm in einer Datei zu speichern. Wir werden nun unser zuvor erzeugtes Array in einer Datei mit dem Kommando savetxt speichern. Eine detaillierte Einführung in diese Thematik findet man im Kapitel
np.savetxt("population_table.csv",
population_table,
fmt="%s;%d;%d;%d",
delimiter=";")
Sehr wahrscheinlich wird man zu einem späteren Zeitpunkt die Daten der eben gespeicherten Datei wieder einlesen wollen. Dies können wir mit dem Kommando genfromtxt bewerkstelligen.
dt = np.dtype([('country', np.unicode, 20),
('density', 'i4'),
('area', 'i4'),
('population', 'i4')])
x = np.genfromtxt("population_table.csv",
dtype=dt,
delimiter=";")
print(x)
Statt genfromtxt kann man auch loadtxt verwenden:
dt = np.dtype([('country',
np.unicode, 25),
('density', 'i4'),
('area', 'i4'),
('population', 'i4')])
x = np.loadtxt("population_table.csv",
dtype=dt,
delimiter=";")
print(x)
Unicode-Strings in Arrays
Wir hatten ja bereits darauf hingewiesen, dass die Strings in unserem vorigen Beispielarray ein kleines b als Präfix hatten. Dies kam dadurch, dass wir in unserer dtype-Definition ('country', 'S20') geschrieben und dadurch unsere Ländernamen als Binärstrings definiert hatten.
Um Unicode-Strings zu erhalten, müssen wir die Definition in ('country', np.unicode, 20) umändern. Wir ändern die Definition für population_table wie folgt:
dt = np.dtype([('country', np.unicode, 25),
('density', 'i4'),
('area', 'i4'),
('population', 'i4')])
population_table = np.array([
('Netherlands', 393, 41526, 16928800),
('Belgium', 337, 30510, 11007020),
('United Kingdom', 256, 243610, 62262000),
('Germany', 233, 357021, 81799600),
('Liechtenstein', 205, 160, 32842),
('Italy', 192, 301230, 59715625),
('Switzerland', 177, 41290, 7301994),
('Luxembourg', 173, 2586, 512000),
('France', 111, 547030, 63601002),
('Austria', 97, 83858, 8169929),
('Greece', 81, 131940, 11606813),
('Ireland', 65, 70280, 4581269),
('Sweden', 20, 449964, 9515744),
('Finland', 16, 338424, 5410233),
('Norway', 13, 385252, 5033675)],
dtype=dt)
print(population_table[:4])
print(population_table.dtype.names)
Das Umbenennen gestaltet sich denkbar einfach. Man weist dieser Property einfach ein neues Tupel mit den neuen Namen zu:
population_table.dtype.names = ('Land',
'Bevölkerungsdichte',
'Fläche',
'Bevölkerung')
print(population_table['Land'])
lands = ['Niederlande', 'Belgien', 'Vereinigtes Königreich',
'Deutschland', 'Liechtenstein', 'Italien', 'Schweiz',
'Luxemburg', 'Frankreich', 'Österreich', 'Griechenland',
'Irland', 'Schweden', 'Finnland', 'Norwegen']
population_table['Land'] = np.array(lands, dtype='<U25')
print(population_table)
Komplexeres Beispiel
In den bisherigen Beispielen haben wir unsere Arrays direkt erzeugt. Normalerweise müssen wir uns jedoch die Daten für unsere strukturierten Arrays aus Datenbanken oder Dateien beschaffen.
Wir werden nun die Liste benutzen, die wir im Kapitel über Dateimanagement erzeugt und gespeichert hatten. Die Liste hatten wir mit Hilfe von pickle.dumpy in der Datei cities_and_times.pkl gespeichert.
Die erste Aufgabe besteht also darin, diese Datei wieder zu ent"pickeln":
import pickle
fh = open("cities_and_times.pkl", "br")
cities_and_times = pickle.load(fh)
for i in range(5):
print(cities_and_times[i])
Nun wandeln wir unsere Daten in ein strukturiertes Array:
time_type = np.dtype([('city', 'U30'),
('day', 'U3'),
('time', [('h', int), ('min', int)])])
times = np.array( cities_and_times , dtype=time_type)
print(times[:4])
lst = []
for row in times:
t = row[2]
t = f"{t[0]:02d}:{t[1]:02d}"
lst.append((row[0], row[1], t))
time_type = np.dtype([('city', 'U30'),
('day', 'U3'),
('time', 'U5')])
times2 = np.array( lst , dtype=time_type)
print(times2[:10])
Nun wollen wir diese Daten in einer csv-Datei speichern. Leider können wir die Funktion np.savetxt nicht nutzen, da diese Funktion nicht mit Unicode-Strings zurechtkommt. Wir benutzen deshalb die normale write-Methode eines File-Streams:
with open("cities_and_times.csv", "w") as fh:
for city_data in times2:
fh.write(",".join(city_data) + "\n")
# prog4book
import numpy as np
mytype = [('produktNr', np.int32), ('preise', np.float64)]
produkte = np.array([(34765, 603.76),
(45765, 439.93),
(99661, 344.19),
(12129, 129.39)], dtype=mytype)
print(produkte[1])
print(produkte["produktNr"])
print(produkte[2]["preise"])
print(produkte)
print(produkte.shape)
# prog4book
verkaufszahlen = np.array([3, 5, 2, 1])
erlöse = produkte["preise"] * verkaufszahlen
print("Erlöse pro Item: ", erlöse)
print("Gesamterlös: ", erlöse.sum())
# prog4book
time_type = np.dtype( [('h', int),
('min', int),
('sec', int)])
times = np.array([(11, 38, 5),
(14, 56, 0),
( 3, 9, 1)], dtype=time_type)
print(times)
print(times['h'])
print(times['min'])
print(times['sec'])
# prog4book
np.column_stack((times['h'],
times['min'],
times['sec']))
# prog4book
time_temp_type = np.dtype( np.dtype([('time', [('h', int), ('min', int), ('sec', int)]),
('temperature', float)] ))
time_temp = np.array( [((11, 42, 17), 20.8),
((13, 19, 3), 23.2),
((14, 50, 29), 24.6)], dtype=time_temp_type)
print(time_temp)
print(time_temp['time'])
print(time_temp['time']['h'])
print(time_temp['temperature'])
# prog4book
with open("time_temp.csv", "w") as fh:
for row in time_temp:
zeit = [f"{el:02d}" for el in row[0]]
zeit = ":".join(zeit)
fh.write(zeit + " " + str(row[1]) + "\n")
!cat time_temp.csv