
 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen

# invisible
import numpy as np
import pandas as pd
np.core.arrayprint._line_width = 60
pd.set_option('display.max_colwidth', 65)
pd.set_option('display.max_columns', 5)
Im vorigen Kapitel haben wir gesehen, dass der Datentyp Series logisch gesehen einer Spalte mit Index einer Excel-Tabelle eintspricht. In diesem Kapitel geht es nun um den Datentyp DataFrame, den man sich nun wie eine komplette Excel-Tabelle vorstellen kann. Man kann also sagen, dass dieser Datentyp auf Tabellen basiert. Ein DataFrame besteht aus einer geordneten Sequenz von Spalten. Jede Spalte besteht aus einem eindeutigen Daten-Typ -- wie eine Series, -- aber verschiedene Spalten können verschiedene Typen haben. So könnte beispielsweise eine Spalte Verkaufszahlen als Float-Zahlen enthalten, während eine andere die zugehörigen Jahreszahlen als Integer-Zahlen enthalten könnte.
Zusammenhang zu Series
Ein DataFrame hat einen Zeilen- und einen Spalten-Index. Es ist wie ein Dictionary aus Series mit einem normalen Index. Jede Series wird über einen Index, d.h. Namen der Spalte angesprochen.
Wir demonstrieren diesen Zusammenhang im folgenden Beispiel, in dem drei Series-Objekte definiert und zu einem DataFrame zusammengebaut werden:
DataFrame
Die grundlegende Idee von DataFrame basiert auf Tabellen. Wir können die Daten-Struktur eines DataFrame als tabellarisch und tabellenähnlich sehen. Ein Dataframe beinhaltet eine geordnete Sammlung von Spalten. Jede Spalte besteht aus einem eindeutigen Daten-Typen, aber verschiedene Spalten haben verschiedene Typen, z.B. könnte die erste Spalte vom Typ Integer sein, während die zweite Spalte vom Typ Boolean ist, usw.
Ein DataFrame hat einen Zeilen- und ein Spalten-Index. Es ist wie ein Dictionary aus Series mit einem normalen Index. Wir demonstrieren dies im folgenden Beispiel, in dem drei Series-Objekte definiert werden:
import pandas as pd
years = range(2014, 2018)
shop1 = pd.Series([2409.14, 2941.01, 3496.83, 3119.55], index=years)
shop2 = pd.Series([1203.45, 3441.62, 3007.83, 3619.53], index=years)
shop3 = pd.Series([3412.12, 3491.16, 3457.19, 1963.10], index=years)
Was passiert, wenn diese "shop"-Series-Objekte konkateniert werden? Pandas stellt eine concat()-Funktion für diesen Zweck zur Verfügung:
pd.concat([shop1, shop2, shop3])
Das Ergebnis ist wohl nicht das, was wir erwartet haben. Der Grund dafür ist, dass concat() für den axis-Parameter 0 verwendet. Probieren wir es mit "axis=1":
shops_df = pd.concat([shop1, shop2, shop3], axis=1)
print(shops_df)
Die Frage ist, von welchem Datentyp das Ergebnis ist:
print(type(shops_df))
Das bedeutet, dass wir Series-Objekte durch Konkatenierung in DataFrame-Objekte wandeln können!
Die Spaltennamen lauten:
shops_df.columns
shops_df.columns.values
Wir geben den Spalten noch Namen, um das DataFrame etwas leichter lesbar zu machen:
cities = ["Zürich", "Winterthur", "Freiburg"]
shops_df.columns = cities
print(shops_df)
Andererseits wäre eine Umbenennung in unserem Fall überhaupt nicht notwendig gewesen, wenn die Series bereits entsprechend benamt gewesen wären. Wir zeigen dies in folgendem Fall:
shop1.name = "Zürich"
shop2.name = "Winterthur"
shop3.name = "Freiburg"
shops_df2 = pd.concat([shop1, shop2, shop3], axis=1)
print(shops_df2)
Auf die Spalten eines Dataframes können wir einfach durch Indizierung zugreifen:
print(shops_df["Zürich"])
Jede einzelne der Spalten entsprach ursprünglich einer Series und entspricht auch immer noch einer Series. Dies können wir sehen, wenn wir uns den Typ anschauen:
print(type(shops_df["Zürich"]))
Pandas bietet noch eine syntaktisch deutlich einfachere Methode, auf die Spalten zuzugreifen. Die Spaltennamen wurden dazu als Properties implementiert, und dies bedeutet, dass man einfach den Spaltennamen mittels Punkt an das Dataframe anhängen kann, um die entsprechende Spalte anzusprechen.
print(shops_df.Zürich)
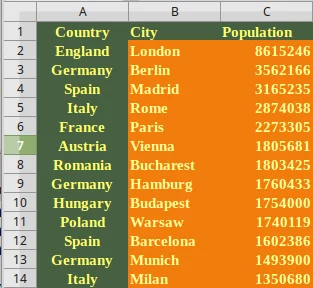
cities = {"name": ["London", "Berlin", "Madrid", "Rome",
"Paris", "Vienna", "Bucharest", "Hamburg",
"Budapest", "Warsaw", "Barcelona",
"Munich", "Milan"],
"population": [8615246, 3562166, 3165235, 2874038,
2273305, 1805681, 1803425, 1760433,
1754000, 1740119, 1602386, 1493900,
1350680],
"country": ["England", "Germany", "Spain", "Italy",
"France", "Austria", "Romania",
"Germany", "Hungary", "Poland", "Spain",
"Germany", "Italy"]}
city_frame = pd.DataFrame(cities)
print(city_frame)
ordinals = ["first", "second", "third", "fourth",
"fifth", "sixth", "seventh", "eigth",
"ninth", "tenth", "eleventh", "twelvth",
"thirteenth"]
city_frame = pd.DataFrame(cities, index=ordinals)
print(city_frame)
Umsortierung der Spalten
Die Sortierung kann zum Zeitpunkt der Erstellung des DataFrame definiert und angepasst werden. Damit kann sichergestellt werden, dass wir eine definierte Sortierung der Spalten haben, wenn das DataFrame aus einem Dictionary erzeugt wird. Dictionaries waren bis Python 3.6 nicht geordnet, wie wir es im Kapitel zu Dictionaries gezeigt haben. Dadurch konnte man bis Python 3.6 nicht wissen, in welcher Reichenfolge die Indizes iteriert worden. Mit dem Parameter columns können wir jedoch eine Reihenfolge festlegen:
city_frame = pd.DataFrame(cities,
columns = ["name",
"country",
"population"])
print(city_frame)
Im Folgenden ändern wir sowohl die Spaltenreihenfolge und die Indexreihenfolge mit der Funktion reindex:
city_frame.reindex(index=[0, 2, 4, 6, 8, 10, 12, 1, 3, 5, 7, 9, 11],
columns=['country', 'name', 'population'])
Jetzt wollen wir die Spalten umbenennen. Dafür verwenden wir die DataFrame-Methode rename. Die Methode unterstützt folgende Konventionen:
- (index=index_mapper, columns=columns_mapper, ...)
- (mapper, axis={'index', 'columns'}, ...)
Wir benennen nun im folgenden Beispiel die Spalten unseres DataFrame in rumänische Bezeichnungen um. Den Parameter inplace setzen wir auf True, damit das DataFrame-Objekt direkt geändert und kein neues erzeugt wird. Der Default-Wert für den Parameter inplace ist False.
city_frame.rename(columns={"name":"Nume",
"country":"țară",
"population":"populație"},
inplace=True)
print(city_frame)
Bestehende Spalte als Index im DataFrame
Wir wollen im nächsten Beispiel einen "nützlicheren" Index für unser Beispiel erzeugen. Dafür verwenden wir die Landesnamen als Index, d.h. die Werte aus der Liste mit dem Key country aus unserem cities-Dictionary. Wir zeigen zuerst, wie man dies direkt bei der Erzeugung des DataFrames bewerkstelligen kann:
city_frame = pd.DataFrame(cities,
columns=['name', 'population'],
index=cities['country'])
print(city_frame)
Man kann auch in einem bestehenden DataFrame den Index neu setzen. Dazu nutzen wir die Methode set_index, um eine Spalte in einen Index zu wandeln. Dabei ist zu beachten, dass set_index ein neues DataFrame zurückliefert, bei dem die gewählte Spalte als Index verwendet wird:
city_frame = pd.DataFrame(cities)
city_frame2 = city_frame.set_index("country")
print(city_frame2)
Im vorherigen Beispiel haben wir gesehen, dass die Methode set_index ein neues DataFrame-Objekt liefert und nicht das originale Objekt verändert. Möchte man kein neues DataFrame erzeugen, sondern das bestehende direkt mit einem neuen Index versehen, so kann man den Parameter "inplace" auf True setzen. Dadurch wird dann das originale Objekt direkt verändert:
city_frame = pd.DataFrame(cities)
city_frame.set_index("country", inplace=True)
print(city_frame)
Selektion von Zeilen
Bis jetzt haben wir die DataFrame-Objekte über die Spalten indiziert, d.h. wir haben nur auf Spalten zugegriffen. Nun möchten wir demonstrieren, wie wir auch selektiv auf die Zeilen zugreifen können. Dazu verwenden wir die Locators loc und iloc.
Im ersten Beispiel erzeugen wir ein Dataframe, das nur aus den Zeilen besteht, in denen wir den Index "Germany" haben:
city_frame = pd.DataFrame(cities,
columns=("name", "population"),
index=cities["country"])
print(city_frame.loc["Germany"])
Will man mehrere Index-Werte angeben, übergibt man diese als Liste an loc:
print(city_frame.loc[["Germany", "France"]])
Nun wählen wir alle Zeilen aus, in denen in einer Spalte eine Bedingung erfüllt ist, also in unserem Beispiel die Bevölkerungsanzahl größer als zwei Millionen ist:
print(city_frame.loc[city_frame.population > 2000000])
Nun berechnen wir die Summe der Bevölkerungszahlen:
city_frame["population"].sum()
Mit cumsum berechnen wir die kumulative Summe:
x = city_frame["population"].cumsum()
print(x)
Spaltenwerte ersetzen
Das eben berechnete 'x' ist ein Series-Objekt mit der kumulativen Summe. Diese Series können wir der population-Spalte zuweisen und ersetzen damit die alten Werte. Im Folgenden nutzen wir die Methode head, die nur die ersten fünf Zeilen ausgibt, da dies zur Veranschaulichung des Prinzips genügt:
city_frame["population"] = x
print(city_frame.head())
Anstelle die Werte in der population-Spalte komplett durch die kumulativen Summen zu ersetzen, wollen wir die neuen Werte als neue zusätzliche Spalte cum_population dem ursprünglchen DataFrame anfügen.
city_frame = pd.DataFrame(cities,
columns=["country",
"population",
"cum_population"],
index=cities["name"])
print(city_frame.head())
Die neue Spalte cum_population enthält nur NaN-Werte, weil noch keine Daten zur Verfügung gestellt wurden.
Nun weisen wir die kumulativen Summen dieser neuen Spalte zu:
city_frame["cum_population"] = city_frame["population"].cumsum()
print(city_frame.head())
Bei der Erstellung eines DataFrame-Objektes aus einem Dictionary können auch Spalten angegeben werden, die nicht im Dictionary enthalten sind. In diesem Fall werden die Werte ebenfalls auf NaN gesetzt:
city_frame = pd.DataFrame(cities,
columns=["country",
"area",
"population"],
index=cities["name"])
print(city_frame.head())
In einem weiteren Schritt kann man dann die Werte für die Fläche in Form einer Liste bzw. eines Arrays an die Spalte area zuweisen.
# Flächen in qkm:
area = [1572, 891.85, 605.77, 1285,
105.4, 414.6, 228, 755,
525.2, 517, 101.9, 310.4,
181.8]
city_frame["area"] = area
print(city_frame.head())
city_frame = city_frame.sort_values(by="area", ascending=False)
print(city_frame)
Nehmen wir an, dass wir lediglich die Flächenwerte von London, Hamburg und Milan hätten. Die areas-Werte befinden sich in einem Series-Objekt mit den korrekten Indizes. Die Zuweisung funktioniert ebenfalls:
city_frame = pd.DataFrame(cities,
columns=["country",
"area",
"population"],
index=cities["name"])
some_areas = pd.Series([1572, 755, 181.8],
index=['London', 'Hamburg', 'Milan'])
city_frame['area'] = some_areas
print(city_frame)
city_frame = pd.DataFrame(cities,
columns = ["country",
"population"],
index = cities["name"])
city_frame.insert(loc = 1,
column = 'area',
value = area)
print(city_frame)
growth = {"Switzerland": {"2010": 3.0,
"2011": 1.8,
"2012": 1.1,
"2013": 1.9},
"Germany": {"2010": 4.1,
"2011": 3.6,
"2012": 0.4,
"2013": 0.1},
"France": {"2010": 2.0,
"2011": 2.1,
"2012": 0.3,
"2013": 0.3},
"Greece": {"2010": -5.4,
"2011": -8.9,
"2012": -6.6,
"2013": -3.3},
"Italy": {"2010": 1.7,
"2011": 0.6,
"2012": -2.3,
"2013": -1.9}
}
growth_frame = pd.DataFrame(growth)
print(growth_frame)
Sie möchten vielleicht die Jahre als Spalten und die Länder als Zeilen?
Eine Vertauschung von Index und Spalten ist mittels transpose ganz einfach zu realisieren:
print(growth_frame.transpose())
Statt transpose() kann man auch einfach die Property-Schreibweise T verwenden:
print(growth_frame.T)
growth_frame = growth_frame.T
growth_frame2 = growth_frame.reindex(["Switzerland",
"Italy",
"Germany",
"Greece"])
print(growth_frame2)
import pandas as pd
cities = ["Vienna", "Vienna", "Vienna",
"Hamburg", "Hamburg", "Hamburg",
"Berlin", "Berlin", "Berlin",
"Zürich", "Zürich", "Zürich"]
data = ["Austria", 414.60, 1805681,
"Germany", 755.00, 1760433,
"Germany", 891.85, 3562166,
"Switzerland", 87.88, 378884]
index = [cities, ["country", "area", "population",
"country", "area", "population",
"country", "area", "population",
"country", "area", "population"]]
city_series = pd.Series(data, index=index)
print(city_series)
city_series = city_series.sort_index()
city_series = city_series.swaplevel()
city_series.sort_index(inplace=True)
print(city_series)
import pandas as pd
persons = { "Name" : ["Henry", "Sarah", "Elke",
"Lulu", "Vera", "Toni",
"Maria", "Chris"],
"Größe" : [179, 165, 172, 154, 150,
189, 176, 175],
"Gewicht" : [65, 58, 58, 45, 43, 99, 68, 60]
}
pdf = pd.DataFrame(persons,
columns = ["Gewicht", "Größe"],
index=persons["Name"])
bmi = (pdf.Gewicht / ((pdf.Größe/100) ** 2))
bmi_okay = pdf.loc[(20 < bmi) & (bmi < 25)]
print(bmi_okay)
pdf.loc[pdf.index.str.contains("i")]
pdf.insert(loc=len(pdf.columns),
column="BMI",
value=(pdf.Gewicht / ((pdf.Größe/100) ** 2)))
pdf
pdf.sort_values(by="BMI", ascending=False)
bmi_okay = (18.5 < pdf['BMI']) & (pdf['BMI'] < 23.5)
name_contains_a = pdf.index.str.contains('a')
print(pdf.loc[bmi_okay & name_contains_a])
import numpy as np
import pandas as pd
names = ['Jonas', 'Leon', 'Finn', 'Guido',
'Lara', "Hannah", "Mila", "Lina"]
index = ["Januar", "Februar", "März",
"April", "Mai", "Juni",
"Juli", "August", "September",
"Oktober", "November", "Dezember"]
df = pd.DataFrame(np.random.randint(120,
200,
size=(len(index),
len(names))),
columns = names,
index = index)
print(df)
new_df = df.transpose()
print(new_df)